従来のデータ利活用コストを約50%削減!
データ仮想化がもたらす これからのデータ環境の在り方
現在、多くの企業がビッグデータを用いた製品開発や業務改革に取り組んでいます。
しかし、当初思い描いていたような成果を得られているでしょうか。
もしビッグデータの利活用において、「データ統合にかかる手間とコスト負荷が大きい」「バッチ処理前のデータを参照できない」といった問題が発生しているならば、運用方法を根本から見直すべきかもしれません。
ここでは、ビッグデータの巨躯から生じるデメリットを打ち消しつつ、利便性の向上につなげる「データ仮想化」のメリットやソリューションを紹介します。

目次
1.データ活用を阻む「データの肥大化」
2.ビッグデータ活用の鍵は「データ仮想化」にあり
3.データ仮想化のROIとTCO
4.データ仮想化サービスの将来性
5.まとめ
1.データ活用を阻む「データの肥大化」
企業で作られるデータは年々増加を続けており、2018年時点で約33ゼタバイト(33兆GB)に達しており(※1)、このうち実に85%以上が、「オリジナルからのデータコピー」と言われています。つまり、多くの企業はビッグデータの複製・抽出・結合といった「データ利活用の前処理」に多大な労力とコストを投じていることになります。このように肥大化を続けるビッグデータは、実際の利活用においても、さまざまな課題につながっています。
|
(※1) 総務省「ICTコトづくり検討会議」(平成25年6月)https://www.soumu.go.jp/menu_seisaku/ictseisaku/ict_koto/index.html |
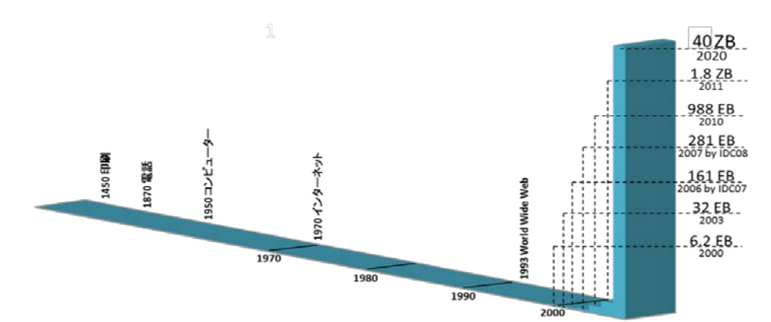
リードタイムとリアルタイム性の課題
これまでのデータ利活用の前処理は、一般的に業務時間外の夜間バッチ処理などで進められてきました。したがって、実際に利活用するデータは数時間から数日前のものになってしまいます。そのため、リアルタイム性を担保しきれていないという課題もありました。
データ分析基盤の構築にかかるコストと時間
これまでのビッグデータ活用では、部門に適したデータを提供するため「データマート(小規模かつ部門単位での利用に適したデータ保管庫)」が用いられてきましたが、ETL処理などで一定の時間を要します。また、データマートは用途ごとに個別に作成することが多いため部門横断型のデータ連携に適しておらず、データのやりとりに必要な権限設定など、別途コストが発生することも見逃せません。こうした労力・コストが、結果的に総運用コストの増大を招いてしまうのです。
バージョン管理の煩雑さ
データソースからDWH、DWHからデータマートへとデータのコピーを繰り返すあまり、データのバージョン管理が煩雑になり、「どのデータが正しいか」を把握しづらくなるという問題も発生します。さらにその先でデータを利活用するユーザーが独自にデータ結合・保存を繰り返した結果、データの信憑性が低下し、思わぬ業務遅滞を招くリスクがあります。また、複数のバージョンのデータを保管することになるため、ストレージ容量を圧迫するという問題も出ます。
分析に適さないデータがセットされる
基幹システム等からDWH等にデータを連携しただけでは、分析精度を高めるための加工(サマライズ等)が行われていません。また、ETLやデータマート、データレイクなど複数の保管庫からデータを抽出・結合するためには、アクセス権限の付与や運用ルールの設定が必須です。こうした処置は、部門や支社を横断したプロジェクトには必ず必要になるため、ビッグデータ活用を阻む原因になり得ます。
2.ビッグデータ活用の鍵は「データ仮想化」にあり
これら、ビッグデータ活用にまつわる種々の課題を解決するためには、「データ仮想化」を基礎としたプラットフォームの活用が望ましいでしょう。
データ仮想化とは
データ仮想化とは、さまざまな種類のデータソースを、ひとつの仮想データレイヤーへと結合し、そこからオリジナルデータと同一のデータをユーザーが活用したいタイミングでスピーディーに提供する技術です。
データ仮想化を活用することによって、データ活用において発生するデータ加工・整形時にデータの物理的なコピーを行うことなく、最新データを必要なタイミングでユーザーへ提供できるようになります。
例えば、企業の業績データを分析して、今後の経営戦略立案を行う場合、営業部門や製造部門など、さまざまな部門のデータが必要になります。それらは大量かつ形式の異なるデータであるため、従来のDWH等ではデータの整形や統合の度に膨大なデータの複製や蓄積が行われ、データを分析できる状態にするまでに時間がかかります。
しかし、データ仮想化を活用することでデータの物理的な複製が不要となり、また元データに手を加えることなくデータの整形や統合が可能となるため、敏速にデータを分析し、経営戦略立案に活用することができます。
|
|

データ仮想化のメリットを整理すると、以下のようなものが挙げられます。
データ仮想化のメリット
メリット1:複製されたデータを保管するための環境が不要
データ仮想化では、物理的なデータ移動を発生させないため、複製後のデータを保管するストレージも不要です。従来のDHWやデータレイクでは、データソースから任意のデータを取得した時点で「複製」が出来上がるため、これを保管するためのストレージが必要でした。さらに、用途に応じてデータを加工する際には、複数のステップを踏むため、複製と蓄積が繰り返されることでストレージが肥大化するという問題もありました。加えて、ストレージを維持するための保守運用の人件費も考慮すると、複製されたデータを保管するための環境にかかるコストは無視できない規模になります。
一方、データ仮想化は「データの複製」「蓄積」というステップを省略できるため、複製したデータを保管するための余分な環境を用意する必要がありません。また「オリジナルデータの参照」「可視化(加工)」のみにリソースを集中できるため、迅速性を担保したデータ活用が可能です。
メリット2:「正のデータ」を喪失しない
データ仮想化では、仮想データレイヤー上でデータの統合や加工を行うため、元データに対する上書きや編集は一切行われません。したがって、バージョン管理の煩雑さや管理の不手際などから生ずる「正のデータの喪失」が発生しません。
メリット3:スピーディーなデータ活用を実現
データ仮想化を用いることにより、従来データ活用のスピードを低下させる原因であった「データの複製」や「正のデータの喪失」等の課題を解決し、必要なデータをユーザーが活用したいタイミングで提供することが可能です。そのため、データ分析やそれにもとづく意思決定・施策の実行などをタイムリーに行うことができ、スピーディーなデータ活用を実現します。
以下は、データ仮想化を用いたデータ活用の一例です。
1.データ仮想化技術を利用したデータレイクに任意のデータソース(クラウド・オンプレミス、フォーマット問わず)を定義する
2.1で定義したデータソースから、任意のデータを取得し、仮想化技術を活用してさまざまなデータを複製することなく活用したい形(データフォーマット)に統合・整形
3さまざまなアプリケーション(BI、MA等)にデータを連携しスピーディーなデータ活用を実現
このように、データ仮想化技術を活用することで、従来であれば上記②の部分で要していた時間やコストを抑えつつ、複数のデータから必要なデータをスピーディーに提供することが期待できます。特に、BIツールを活用したデータ分析・可視化や、MAツールを活用したさまざまなマーケティング施策実行のスピードアップが期待できるため、ビジネスにおけるスピーディーな意思決定の実現につながります。
3.データ仮想化のROIとTCO(※2)
データ仮想化のリーダー企業であるDenodoTechnologiesによると、コピーデータのうち、75%は誰もが使っていないデータで、年間約75億円のコストがムダになっているという事例があります。これが、ビッグデータ利活用の費用対効果が上がらない原因のひとつでもあります。
DenodoTechnologiesによると、データ活用において、データ仮想化を活用することで、都度発生していたデータコピーを削減し、上記の45%、年間約34億円を削減することが可能という事例もあります。
さらに、データプレパレーションを併用することで、データ整形やクレンジングなど、データ準備作業にかかる人的負荷を50%以下に削減することも可能です。
(※2) TCO:Total Cost of Ownership コンピューターシステム構築の際にかかる初期コストから、運用に関わる管理費や人件費等に至るまでのシステムの総所有コスト
4.データ仮想化サービスの将来性
最後に、データ仮想化の将来性について解説します。全世界のデータ仮想化市場は、2016年時点で約37億米ドルであり、2021年には約2倍の67億米ドル規模まで拡大すると予測されています。
この背景には、AIによるデータ活用需要の増大があります。多くの企業でAI活用が広まる一方、AI活用において必要なデータの整備が進んでおらず、ビジネスユーザーが自ら手作業でデータの整形・加工などを行うケースも多々あります。
総務省の「平成29年版 情報通信白書(※3)」によれば、世界の企業のうち約半数がデータ利活用の課題・障壁として「データ収集・管理コストの増大」を挙げています。
こうした実情からも、データ活用のための環境を整備し、データの整形や加工を容易に行うことができるアプリケーションとシームレスに連携したデータ仮想化サービスが求められています。
|
(※3) 総務省「平成29年版 情報通信白書」(平成29年)https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/h29/html/nc122310.html |
5.まとめ
本稿では、ビッグデータ活用における課題やデータ仮想化のメリットなどを解説してきました。ビッグデータ活用は、データウェアハウスやデータレイクなど、種々のソリューションによって進化を続けてきました。
しかし、これらはコスト・時間の面で徐々に企業の負担を大きくするという実情があります。データ仮想化は、既存のビッグデータソリューションのメリットはそのままに、コストパフォーマンス・迅速性を高めたソリューションです。
ビッグデータ活用をより強力に推進するための基盤として、データ仮想化サービスを検討してみてはいかがでしょうか。
※2020年4月時点の情報です。
